PEP 6305 Measurement in
Health & Physical Education
Topic 11:
Reliability
Section 11.1
n
This Topic has 3 Sections.
Reading
n
Vincent & Weir, Statistics in Kinesiology, 4th ed. Chapter
13 “Quantifying Reliability”.
n
Also, the
"Reliability" PDF reading posted in Blackboard.
Purpose
n
To discuss the principles of reliability and measurement error.
n
To demonstrate the estimation of reliability and the standard
error of measurement.
Objectivity
n
Objectivity concerns how a test is scored. It depends on
two factors:
¨
A defined scoring system.
¨
Individuals (called judges or raters) who have been trained to score the test.
n
An objective test is one that two or more competent
judges assign the same value when scoring a test. In other words,
whether the judges agree on the rating.
¨
The training of the judges and the scoring system are important
to achieving high reliability.
¨
For example, if multiple judges score an event, such as
gymnastics or diving, you would need a scoring system that not only includes
what would be important, but also how to assign points (a scale), and scorers would have
to be trained on what to observe and how to assign points.
n
Objectivity is sometimes referred to as interrater reliability.
n
An objective rating is always better than a
subjective rating because less measurement
error is introduced.
¨
Differences between multiple test scorers introduces measurement error.
¨
Increasing measurement error decreases objectivity (interrater reliability); decreasing
objectivity, in turn, decreases validity (Validity is the final course Topic).
Reliability
n
Reliability concerns how accurately a test represents
variation between subjects.
n
Measurement theory: An observed score (X) consists of two
components, a true score (T) and error score (E):
¨
X = T + E
¨
T (true score) is the measure of the ability or characteristic that we are interested in.
¨
E (error score) is measurement error, which is anything that is NOT the thing we
want to measure.
n
There are several possible sources of
measurement error:
¨
Measurement unit or scale – a test’s unit of measurement
may be too large to measure the characteristic precisely. For example, if
subjects are rated on a three point scale (poor, average, excellent), then
distinguishing between subjects within any of the three ratings would be
impossible, although it is unlikely that all subjects who received the same
rating have exactly the same ability: not everyone who is rated "excellent" is
performing exactly the same, so giving them all the same score introduces some
error (deviation from their "true" score or ability).
¨
Subject inconsistency – a person could have a good or bad
day when being tested, which means their performance differs from day to day.
¨
Poor test conditions – noise or other distractions when
taking a written test or a slippery condition when taking a running test. Poor
conditions rather than the subject's ability affect the subject's score.
¨
Poorly constructed test – writing bad test questions that
no one can understand so that the test takers end up guessing. Guessing is not a
measure of academic ability.
¨
Poor test equipment – The equipment (e.g., the gas analyzer
when measuring VO2) is inconsistent because it is malfunctioning or improperly
calibrated.
n
Theoretically, you could determine a person’s true score (T) by
calculating the mean of an infinite number of tests.
¨
While it is not possible to administer a test an infinite number
of times, it is important to understand that the mean of several administrations
(or trials) is the most accurate representation of the subject's true
score.
Why? In general (but not always), the more trials you have, the more
accurate (reliable) is the average score with respect to the subject's true
score -- it is more reliable.
¨
Measurement error is assumed to be random and
normally
distributed. Thus, the mean error over several trials will be 0, with
predictable
variability on either
side of 0.
Interpreting Test
Reliability
n
A reliability coefficient represents the proportion of total variance that
is measuring true score differences among the subjects.
¨
A reliability coefficient can range from a value of 0.0 (all the
variance is measurement error) to a value of 1.00 (no measurement error).
In reality, all
tests have some error, so reliability is never 1.00.
¨
A test with high reliability (≥0.70) is desired, because lower
reliability indicates that a large proportion of test variance is measurement
error.
¨
If test reliability is 0, and test scores are used to assign grades, a
student's grade would be assigned purely by chance, similar to flipping a coin
or rolling dice!
n
High reliability indicates that the test is measuring something;
validity studies (Topic 12) determines what the test is measuring.
¨
High test reliability is required for test validity. A test cannot
be valid if it is not reliable.
¨
Low reliability means most of the observed test variance is measurement error –
due to chance.
¨
If test variance is largely due to chance, it is not measuring
anything.
¨
If a test is not measuring anything, it cannot be a
valid measure of anything.
Determining Reliability
n
Test reliability is always established for a defined population;
reliability of a test in one population may not be the same as in other populations.
¨
Test
variance
is central to reliability.
¨
Since a test score (X) consists of true and error components, the
total variance (σx2) of a test administered to a group
consists of true score variance (σt2) and error variance
(σe2):
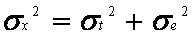 Test
Variance = True Score Variance + Error Variance
Test
Variance = True Score Variance + Error Variance
n
To illustrate, suppose the SD of a test administered to students
was 2.0 (thus, total test variance = 2.02 = 4.0). All of the students
guessed on every question, which means that getting the questions correct was
due to luck or chance
(σe2 = 4.0). Since guessing is completely random
and has nothing to do with ability (true score), there would be no
true score variance (σt2 = 0) and the
components would be:
¨
Total Variance = True Score Variance + Error Variance: 4.0 = 0.0 +
4.0
n
Test reliability (Rxx) is calculated from these
variances:

¨
For this example test reliability would be: Rxx = [(4.0
– 4.0)/4.0] = 0/4.0 = 0.0
¨
The reliability of this test is 0, which means that all test
variance was due to measurement error. The test did not measure anything.
n
As another example of test reliability, let us assume we have a
test with a total variance of 40 and error variance is 4. If this were the case
we would have the following:
¨
The reliability of the test would be: Rxx = [(40 –
4)/40] = 36/40 = 0.90.
¨
The test reliability would be 0.90. 90% of the test variance is
attributable to true score differences; only 10% of the total test variance was
due to measurement error. This test has good reliability for detecting
differences among subjects for the ability or trait being measured.
Types of
Reliability
Stability or
“Test-Retest” Reliability
n
Involves administering the same test on two or more different
occasions.
n
Typically the tests are administered within a 7-day period to
ensure that true score does not change in the testing period.
n
This method can be used with any test, but is often used with
tests that cannot be administered twice within the same day. An example would be
an endurance test like the 1.5-mile run.
n
The stability reliability of a scorer (i.e., comparing multiple
scores assigned by a single judge) is called intrarater reliability
(how is this different from interrater
reliability, or objectivity?
Internal Consistency
Reliability
n
This type of test involves getting multiple measures within a
day, usually at a single testing session. Examples are:
n
Written test. The items are the multiple measures. The
person’s score is the sum of all items answered correctly.
n
Psychological instrument. These survey or interview instruments consist of
several items that are often scored with 1 to 5 points. The person responds on a
5-point scale describing how characteristic the described behavior is of the
person responding to the scale. The person’s score is usually the sum of all items.
n
Judge's Ratings. A judge rates the performances of several
individuals. Some examples are: figure skaters, divers, gymnasts; allied health
students performing clinical procedures; or high school students who try for the
drill team or cheerleader squad. The judge rates several aspects of the
performance, such as the components of a figure skating routine or competitive
dive; each aspect is rated independently of the other aspects. The final score
is typically the sum or average of the judge's ratings. (Comparing the final scores
between multiple judges is objectivity.)
n
Multiple-trial test. Many motor performance tests can be
administered several times within a day. Examples of this are isometric strength
tests. The test requires the subject to exert maximum effort for six seconds.
The recommended test procedure is to administer a warm-up trial and 50% effort
and then two trials at maximum effort. The average of the two maximum trials is
the individual's score.
 Click
to go to the next section (Section 11.2)
Click
to go to the next section (Section 11.2)